I am trying to quantify the number of mapped reads on CDS regions using samtools idxstats.
I want the number of reads mapped onto CDS produced using TransDecoder taking unigenes as input. Unigenes were obtained using CD-HIT clustering of assembled transcripts using Trinity.
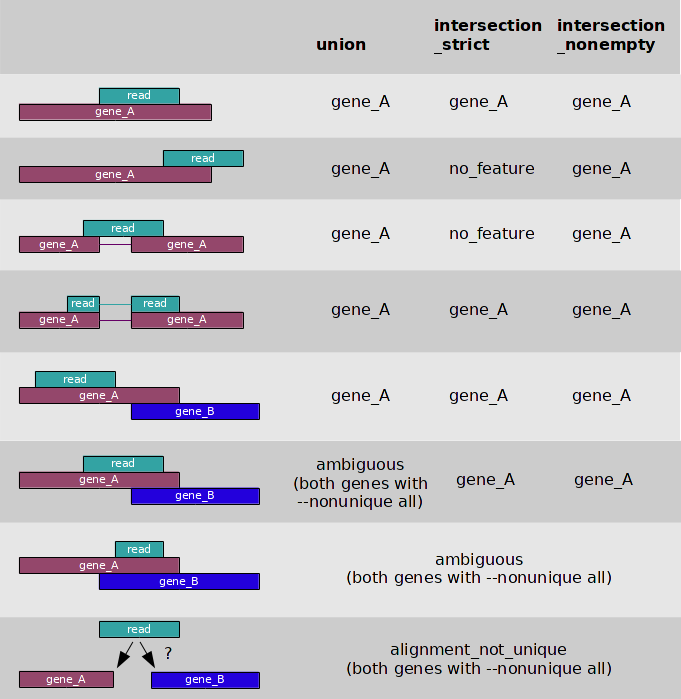
I want to know how samtools idxstats consider reads as "mapped"? I am referring to HT-seq like conditions. Since, I don't have GTF, I am thinking to use samtools idxstats.
In SAM/BAM/CRAM files a read is considered mapped if bit 4 in the flag is not set. The total number of these is stored in BAM file indices, which is what samtools idxstats is reading. Note that how appropriate it is to use this number is dependent on whether you've filtered secondary alignments and what you tend to do with the value.
Thanks Devon, the intention is to use this number as "raw read count" to perform differential expression analysis. Unlike HTSEQ, samtools idxstats is a very crude way (I think) to do so. I wanted to know how samtools decide if a read is mapped i.e. whether a read is considered mapped even if one base is mapped? What about a read that maps to 2 different genes partially. HTSEQ takes care of the same.
What is a better method/tool to take the raw reads counts in case of denovo transcriptome assembly. RSEM is there, however, it takes the transctriptome assembly from Trinity. What I have is CDS predicted from TransDecoder taking Unigenes as input.
I'd just use salmon. You could filter the BAM file and then use samtools idxstats, but for a transcriptome this will likely be throwing away a good bit of useful info that salmon or kallisto would be able to use.
this tool uses the bam index to quickly predict the CNV regions:
The bam index stores a linear index for each chromosome indicating the file (and virtual) offset for every 16,384 bases in that chromosome. Since we know the total number of 16,384 base intervals in the index and the size of the bam file (from the last file offset stored in the index), we know the average size (in bytes) of taken by each 16,384 base chunk. So, we iterate over each (16KB) element in the linear index, subtract the previous file offset, and scale by the expected (average) size. This gives the scaled value for each 16,384-base chunk. There are many ways that this value can be off, but, in practice, it works well as a rough estimate.



{kind=link}
Not not_mapped is mapped as per samtools logic, as I understand